 Access the Graph dataset
Access the Graph datasetWhat is the OpenAIRE Graph?
The OpenAIRE Graph is a free and open resource that brings together and interlinks hundreds of millions of metadata records from over 100k data sources trusted by researchers. The project broke ground in 2012 being one of the first research knowledge graphs and has now grown into one of the world's largest and is the authoritative source for the European Open Science Cloud (EOSC). Here, researchers, communities, institutions, companies, and citizens thrive by freely sharing research products and related information.
Why the need?
As Open Science gradually becomes the norm in research, the way researchers collaborate, publish, discover, and access scientific knowledge has been changing.
For the past decade, researchers have been increasingly publishing research products beyond the article, to share all scientific products generated during experiments or research projects. These include research data, research software, experiments, and other research outputs.
These are then published in scholarly communication data sources (e.g., data archives, institutional repositories, research software repositories), rely where possible on persistent identifiers (e.g., DOI, ORCID, Grid.ac, PDBs), and specify meaningful links to other research products (e.g. supplementedBy, citedBy, versionOf), projects, and funders.
By following such practices, researchers are implicitly constructing a Global Open Science Graph.
The OpenAIRE Graph is available and obtained as a collection of this metadata and links, which are then further enriched with even more metadata and links.

Where is it used?
Scientific Discovery
The Graph is used in the OpenAIRE EXPLORE service, enabling users to efficiently search and navigate through an interconnected research ecosystem. Additionally, it serves as the primary resource supporting the exploration and recommendations in the EOSC EU Node (EOSC Portal).
Bibliometrics
Used for research evaluation in replacement of proprietary databases such as Web of Science or Scopus, with several benefits, including openness and transparency, embedded citation metrics and indicators, access to information beyond publications such as data and software, and the ability to easily integrate your own databases. Get a glimpse in OpenAIRE MONITOR.
Open Science Monitoring
The Graph maintains data related to monitoring Open Access and Open Science policies. It is currently used in services such as the Open Science Observatory, the EOSC Observatory, and the Irish National OA Monitor. Also check OpenAIRE MONITOR to view out of the box indicators for organisations.
The Data Model
In a nutshell, the main entities are:
- Research Products: outcomes of research activities.
- Data Sources: sources from which the metadata of Graph objects are collected.
- Organisations: companies or research institutions involved in projects, responsible for operating data sources or consisting of the affiliations of Product creators.
- Grants: research project grants funded by a Funding Stream of a Funder.
- Communities: groups of people with a common research intent (e.g. research infrastructures, university alliances).
- Persons: individual researchers who are involved in the design, creation or maintenance of research products. Currently, this is a non-materialized entity type in the Graph, which means that the respective metadata (and relationships) are encapsulated in the author field of the respective research products.
How is the OpenAIRE Graph made?
Governance
The OpenAIRE Graph is a public good which operates under community governance.
This effort is spearheaded by OpenAIRE AMKE, a non-profit organisation comprising 47 member entities representing academic and research institutions dedicated to advancing Open Science.
Through its participatory governance model, OpenAIRE AMKE facilitates the endorsement, adoption, operation, and long-term viability of the Graph within its member base, national contexts, and broader research communities.
A complex aggregation-enrichment-deduplication workflow

Using the OpenAIRE Guidelines and the metadata validation mechanism in PROVIDE, the OpenAIRE Graph aggregates millions of metadata records collected from trusted data sources that facilitate Open Science.
- Repositories registered in OpenDOAR, re3data.org, and FAIRSharing.org
- Journals registered in DOAJ
- Pre-print servers
Examples of metadata providers include
Crossref
Unpaywall
ORCID
Microsoft Academic
PubMed
DataCite
OpenCitations
UsageCounts
The content then goes through a deduplication process utilising PIDs and other features of entities.
Additionally, the Graph team enriches the data in two main ways:
- Adding author information from ORCID
- Analysing full-text documents to extract citations and relevant connections (e.g. projects, data, software references)
This analysis helps classify research according to Fields of Science and Sustainable Development Goals (SDGs), and establish citation relationships. The information is also analysed to produce statistics for the OpenAIRE MONITOR, and the Open Science Observatory.
The in-depth enrichment and deduplication stages in this workflow allow for a knowledge graph that not only includes a comprehensive dataset but also enhances the overall data quality.
Harnessing the power of AI
To enrich the OpenAIRE Graph, we use a state-of-the-art AI-driven analytical workflow, which is constantly being expanded through partnerships with publishers and AI experts.
Enriching Metadata
Metadata of research artefacts is enriched by adding additional information, such as authors' ORCID and organisation IDs, Fields of Science classifications, objects' Open Access status, and links to similar artefacts.
Identifying Relationships
Relationships, such as affiliation, co-authorship, citations (between publications, data, software) and funding, are identified between research objects.

Providing Recommendations
Recommendations are provided for related research objects, funding opportunities, and collaborators.
Facilitating Data Analysis
Structured and interconnected views of research data are provided which can be used to identify trends, patterns, and relationships in research data. Different types of citation indexes are computed and added into the records.
The Infrastructure
A Big Data Infrastructure
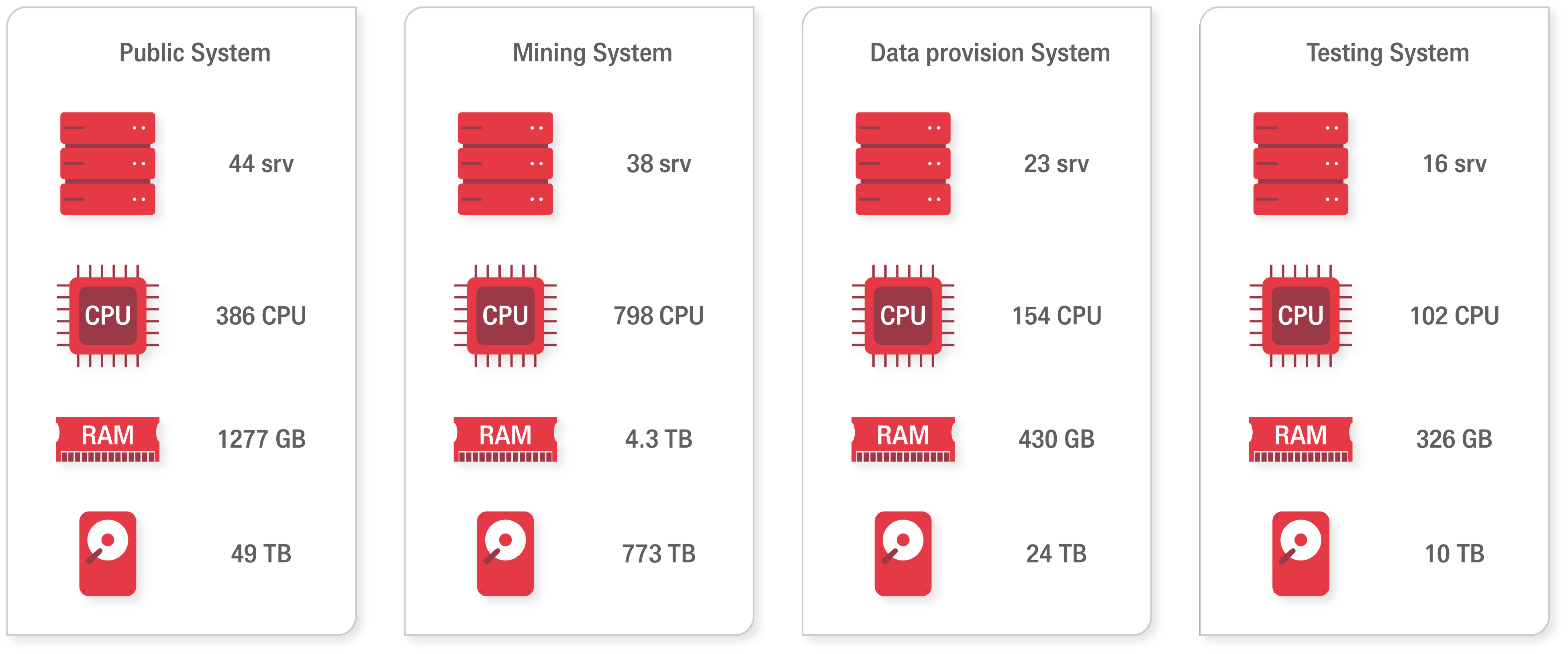
ICM supports the continuous operation of the infrastructure including data aggregation, deduplication, inference, and provision, ensuring seamless 24/7 system uptime and availability. System administration activities cover hardware maintenance and provisioning of the new computational resources, providing high availability solutions to address resilience to failures by service-level redundancy and load balancing to distribute workloads uniformly across servers.
The most crucial parts of the persisted graph are covered with backups along with their well-defined restoration procedures. All the monitoring activities rely on an aggregated system-level monitoring accessible via various dashboards, giving a better overview of system stability and potential requirements for system elements extension. System level monitoring is supplemented with monitoring availability of all the publicly accessible endpoints. Hence, the high standards of the OpenAIRE public API.
All the maintenance operations undertaken by experienced system administrators are founded on well established routines and emergency maintenance procedures.
Access the OpenAIRE Graph
You may access the Graph data in the different ways seen below, but also via our value added services such as EXPLORE, MONITOR, CONNECT. We are currently investigating access via different commercial cloud services.
Unauthenticated Requests
- Direct Downloads from Zenodo - 6 month updates
- REST API with up to 60 request per hour
- Email Support
Authenticated Requests
- REST API with up to 7200 requests per hour
- Access to all enrichments, metrics, with trust measures
- Technical Support