Research products
Duplicates among research products are identified among results of the same type (publications, datasets, software, other research products). If two duplicate research products are aggregated one as a dataset and one as a software, for example, they will never be compared and they will never be identified as duplicates. OpenAIRE supports different deduplication strategies based on the type of results.
The next sections describe how each stage of the deduplication workflow is faced for research products.
Candidate identification (clustering)
To match the requirements of limiting the number of comparisons, OpenAIRE clustering for research products works with two different strategies based on entity types:
Software
- Title extraction functions:
two clustering functions are applied to the title (normalized, stemming, etc.)
- stats and suffix prefix of words: the function generates a key that
depends on (i) number of significant words in the title, (ii) module 10 of
the number of characters of such words, and (iii) a
string
obtained as an alternation of the function prefix(3) and suffix(3) (and
vice-versa) on the first 3 words (2 words if the title only has 2). For
example, the title
Search for the Standard Model Higgs Bosonbecomes the two keys5-3-seaardmodand5-3-rchstadel - n-grams: the function generates ngrams from the
title. For example, the
title
Search for the Standard Model Higgs Bosonbecomes the keystan,sta,ode,mod,ear,hig,igg,sea
- stats and suffix prefix of words: the function generates a key that
depends on (i) number of significant words in the title, (ii) module 10 of
the number of characters of such words, and (iii) a
string
obtained as an alternation of the function prefix(3) and suffix(3) (and
vice-versa) on the first 3 words (2 words if the title only has 2). For
example, the title
- DOI extraction function: the function generates the DOI when this is provided as part of the record properties
- URL extraction function: the function generates the hostname part provided by the URL of the software, if any
Publication, Dataset and Other Research Product
- PID extraction function: the function generates the PIDs when at least one
is provided as part of the
pidrecord properties - Author and Title extraction function: the function generates a key that
depends on (i) the number of authors of the product, with a cap of 21
authors (ii) number of significant words in the title (normalized, stemming,
etc.), divided by 10, and (iii) a string obtained as an alternation of the
function prefix(3) and suffix(3) (and vice versa) on the first 3 words (2
words if the title only has 2).
For example, a product composed by 197 authors and titled ``Search for the Standard Model Higgs Boson`` becomes the two keys ``21-0-seaardmod`` and ``21-0-rchstadel``
Duplicates identification (pair-wise comparisons)
Comparisons in a block are performed using a sliding window set to 50 records. The records are sorted lexicographically on the normalized version of their titles. The 1st record is compared against all the 50 following ones using the decision tree, then the second, etc. Local information about matching records is kept and possibly used to prune unneeded comparisons, for example once it is known that A equals to both B and C, B will not be compared against C because the A,B,C group will be anyway discovered by the global transitive closure step later.
A different decision tree is adopted depending on the type of the entity being processed. Similarity relations drawn in this stage will be consequently used to perform the duplicates grouping.
Publications
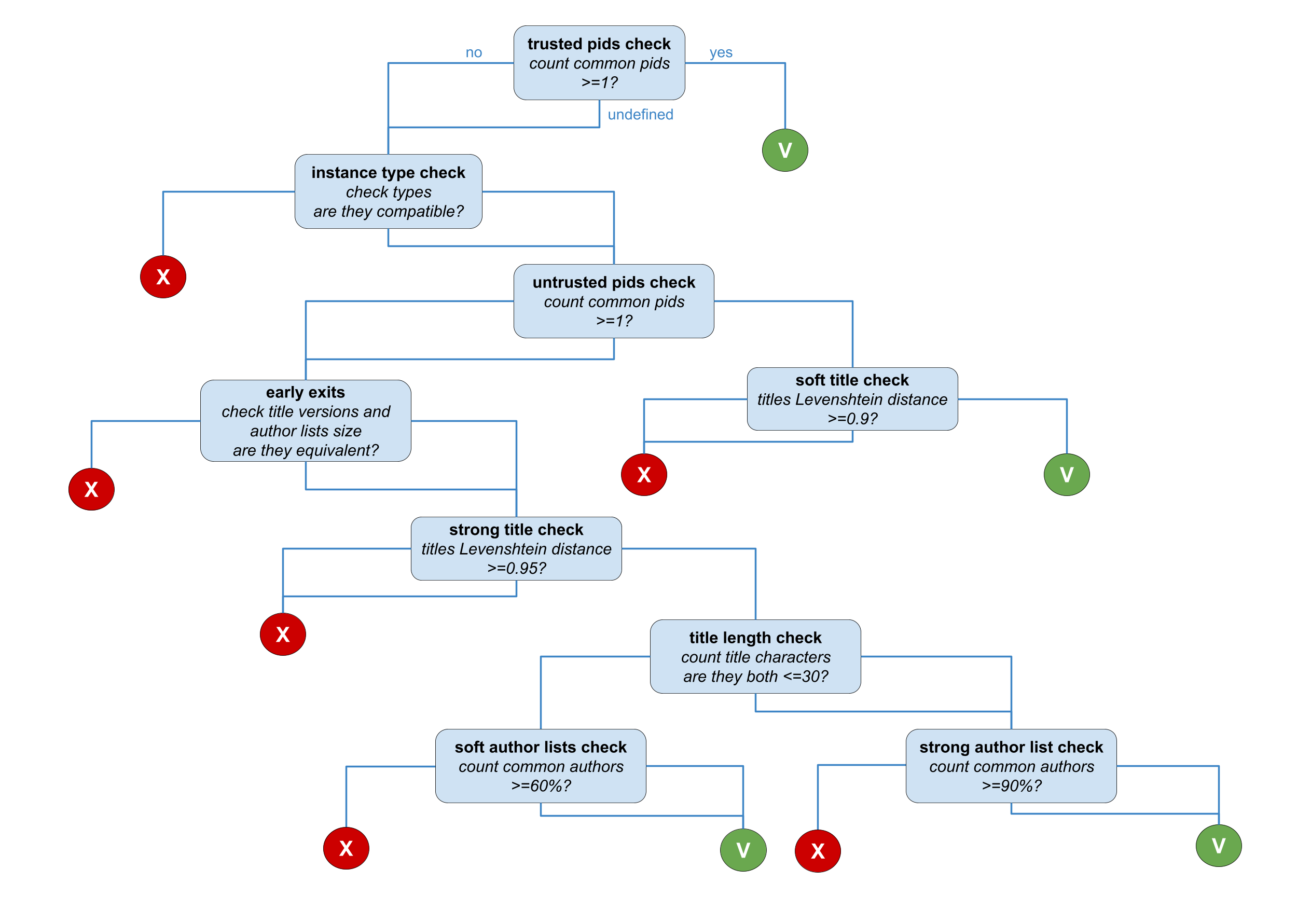
For each pair of publications in a cluster the following strategy (depicted in the figure below) is applied. The comparison goes through different stages:
- trusted pids check: comparison of the trusted pid lists (in the
pidfield of the record). If at least 1 pid is equivalent, records match and the similarity relation is drawn. - instance type check: comparison of the instance types (indicating the subtype of the record, i.e. presentation, conference object, etc.). If the instance types are not compatible then the records does not match. Otherwise, the comparison proceeds to the next stage
- untrusted pids check: comparison of all the available pids (in the
pidand thealternateidfields of the record). In every case, no similarity relation is drawn in this stage. If at least one pid is equivalent, the next stage will be a soft check, otherwise the next stage is a strong check. - soft check: comparison of the record titles with the Levenshtein distance. If the distance measure is above 0.9 then the similarity relation is drawn.
- strong check: comparison composed by three substages involving the (i) comparison of the author list sizes and the version of the record to determine if they are coherent, (ii) comparison of the record titles with the Levenshtein distance to determine if it is higher than 0.95, (iii) "smart" comparison of the author lists to check if common authors are more than 60% in case of titles whose length is greater than 30 chars or more than 90% otherwise.
Datasets and Other types of research products
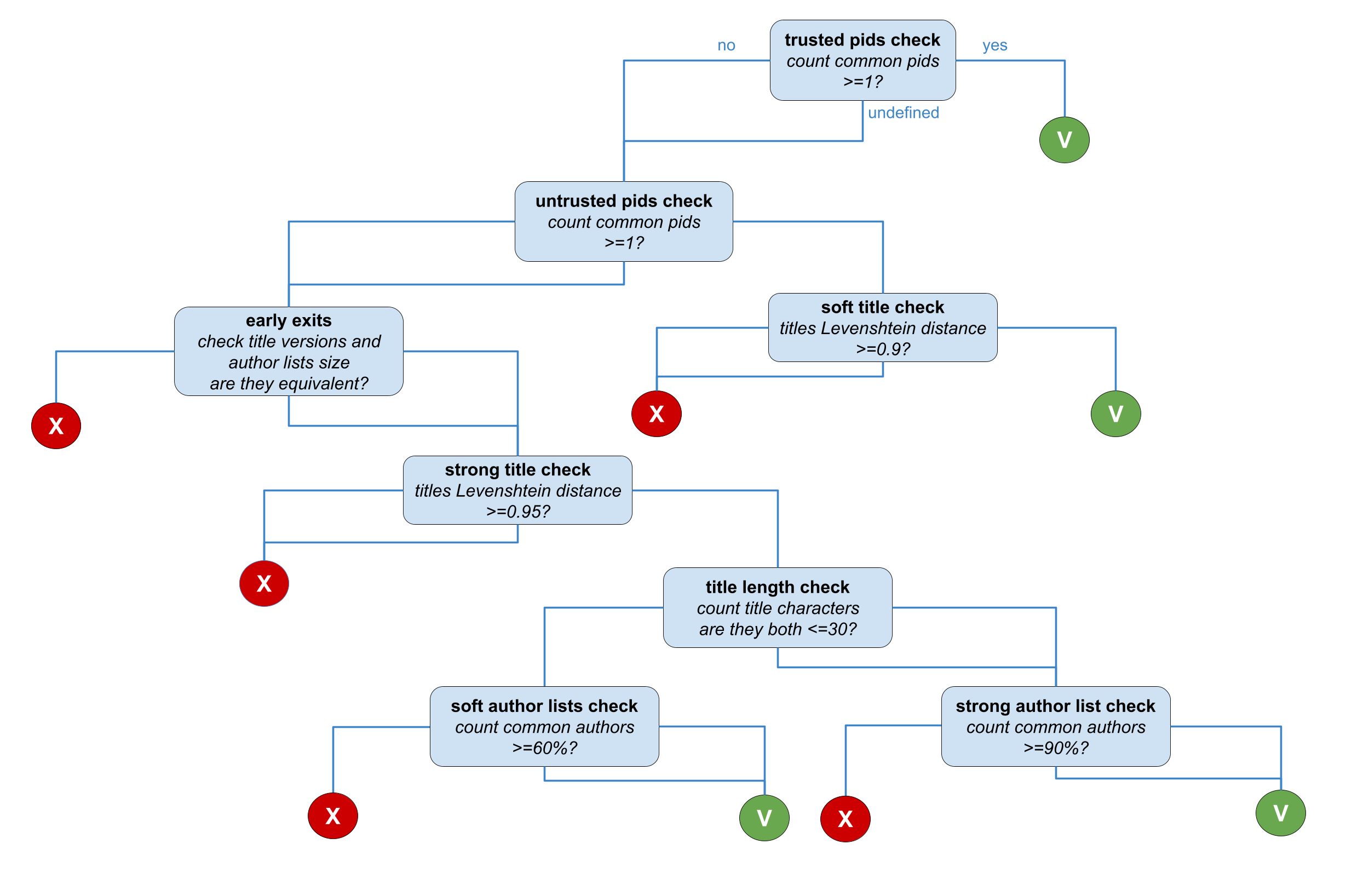
For each pair of datasets or other types of research products in a cluster the strategy depicted in the figure below is applied. The decision tree is almost identical to the publication decision tree, with the only exception of the instance type check stage. Since such type of record does not have a relatable instance type, the check is not performed and the decision tree node is skipped.
Software
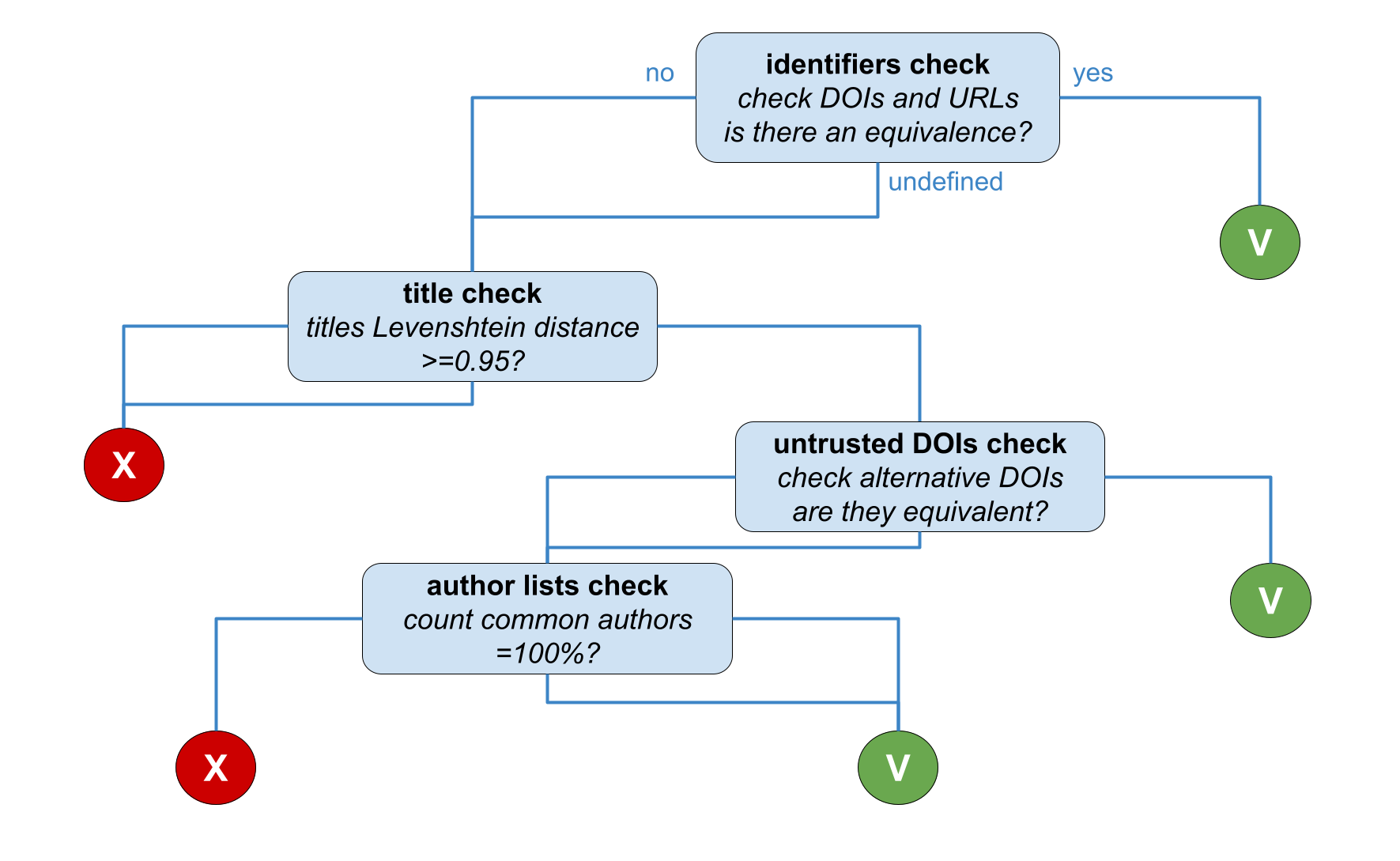
For each pair of software in a cluster the following strategy (depicted in the figure below) is applied. The comparison goes through different stages:
- DOI pids and URLs check: comparison of the pids of type DOI and URLs in the records. If at least 1 DOI is equivalent or 1 URL is equivalent, then records match and the similarity relation is drawn
- title check: comparison of the record titles with Levenshtein distance, excluding versioning information. If the distance is below 0.95 then the records does not match. Otherwise, the comparison proceeds to the next stage
- untrusted DOI check: comparison of all the available DOIs (in the
pidand thealternateidfields of the record). If at least 1 DOI is equivalent, records match and the similarity relation is drawn - authors check: "smart" comparison of the author lists to check if the two products share all authors
Duplicates grouping
The aim of the final stage is the creation of records that group all the equivalent entities discovered pairwise by the previous step. This is done in multiple phases.
Transitive closure
As the concluding step of duplicate identification, a transitive closure is performed against similarity relations to identify complete groups of duplicated records (cliques). If a group exceeds 200 elements, only the first 200 elements are included in the group, while the remaining elements are kept ungrouped.
Selection of the pivot record
Each group of duplicate records needs to be identified in the final graph with an OpenAIRE identifier, derived from a record of the group known as the pivot record. It is determined after sorting the group of duplicate records by the following criteria:
- Records with identifiers from a PID authority.
- Records chosen as pivots in the graph's previous generations.
- Publications from CrossRef or datasets from DataCite.
- Records with an earlier date of acceptance.
- Records with smaller IDs in lexicographical order.
The first sorting criterion is possible because a state table, called "pivot history", is maintained across graph generations. It keeps track of which records were used as pivot records in what graph, guaranteed to retain data for the last 12 months.
Creation of representative records
The representative record, also known as the "dedup record", replaces the group of deduplicated records in the graph.
OpenAIRE identifier of the representative record
The OpenAIRE identifier of the representative record is generated based on the identifier of the record chosen as the pivot of the group:
- if the pivot record comes from a "PID authority", the identifier of the
representative record is the same, but the "PID Type Prefix" part of the
identifier is modified to append
_dedup.
For exampledoi_________::d5021b53204e4fdeab6ff5d5bc468032will becomedoi_dedup___::d5021b53204e4fdeab6ff5d5bc468032 - otherwise the "PID Type Prefix" part will be set to the fixed value
dedup_wf_002, and the following hash will be calculated as the MD5 hash of the entire raw id of the pivot record.
For exampleDansKnawCris::0829b5191605bdbea36d6502b8c1ce1gwill becomededup_wf_002::345e5d1b80537b0d0e0a49241ae9e516
Content of the representative record
The representative records inherits properties from the records it merges
and tracks their provenance. Whenever possible, it preserves all data from the
merged records, such as the instance field. In cases where a specific value
must be chosen, the most representative one is selected. For example, for the
"dateofacceptance" field, the earliest value is chosen.
Merged and singleton representative record
Changes in metadata content or graph construction may lead to cases where representative records disappear from the graph:
- When two or more representative records are merged into one representative record. Put it other terms this happens when a group of duplicated records contains multiple records formerly used as pivot record.
- When a record chosen as a pivot record leaves its group and remains alone.
- When a record chosen as a pivot record is no longer published by its data source (deletion of the metadata record).
To address these cases, the pivot history table ensures the visibility of disappearing representative records for the first two cases. Specifically:
- In the case of merged representative records, the new representative record and the ones that would be lost are generated and linked as part of the new representative record.
- In the case of a record no longer serving as a pivot, a representative record is generated and linked only with that record.
This approach ensures that users can access representative records that would otherwise be lost.