Research results
Duplicates among research results are identified among results of the same type (publications, datasets, software, other research products). If two duplicate results are aggregated one as a dataset and one as a software, for example, they will never be compared and they will never be identified as duplicates. OpenAIRE supports different deduplication strategies based on the type of results.
The next sections describe how each stage of the deduplication workflow is faced for research results.
Candidate identification (clustering)
To match the requirements of limiting the number of comparisons, OpenAIRE clustering for research products works with two functions:
- DOI-based function: the function generates the DOI when this is provided as part of the record properties;
- Title-based function: the function generates a key that depends on (i) number of significant words in the title (normalized, stemming, etc.), (ii) module 10 of the number of characters of such words, and (iii) a string obtained as an alternation of the function prefix(3) and suffix(3) (and vice versa) on the first 3 words (2 words if the title only has 2). For example, the title
Search for the Standard Model Higgs Bosonbecomessearch standard model higgs bosonwith two keys key5-3-seaardmodand5-3-rchstadel.
To give an idea, this configuration generates around 77Mi blocks, which we limited to 200 records each (only 15K blocks are affected by the cut), and entails 260Bi matches.
Duplicates identification (pair-wise comparisons)
Comparisons in a block are performed using a sliding window set to 50 records. The records are sorted lexicographically on a normalized version of their titles. The 1st record is compared against all the 50 following ones using the decision tree, then the second, etc. for an NlogN complexity. A different decision tree is adopted depending on the type of the entity being processed. Similarity relations drawn in this stage will be consequently used to perform the duplicates grouping.
Publications
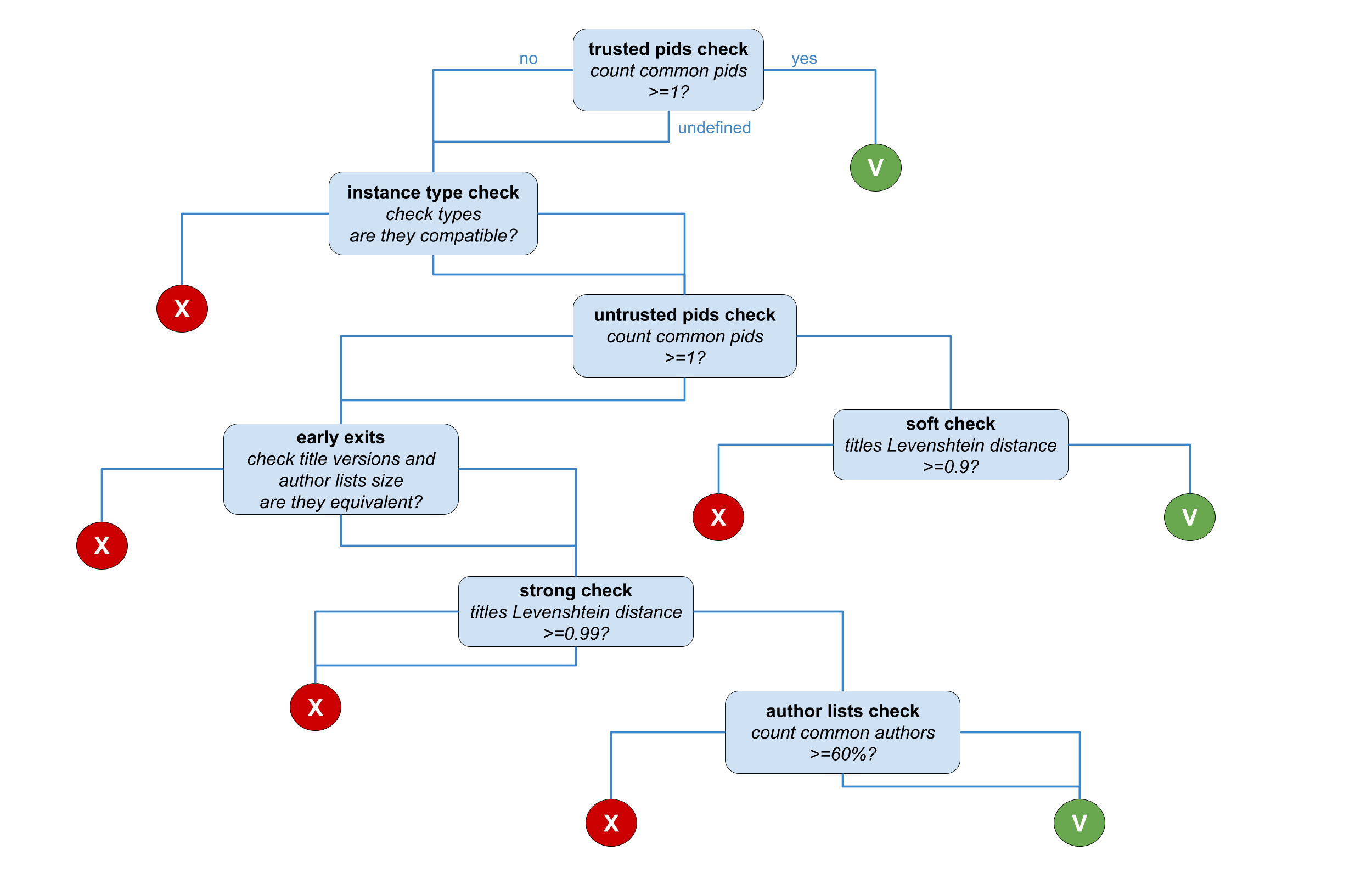
For each pair of publications in a cluster the following strategy (depicted in the figure below) is applied. The comparison goes through different stages:
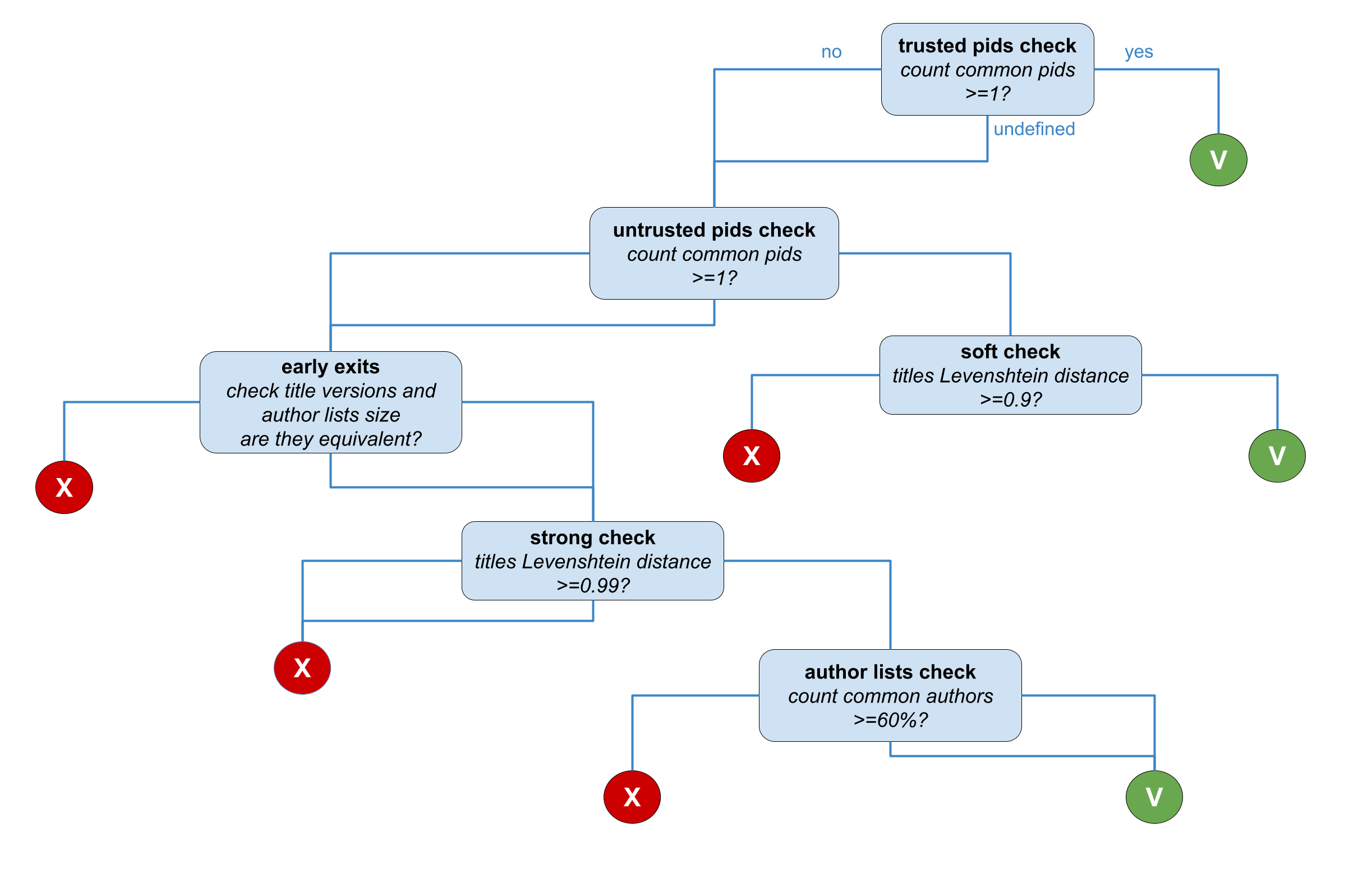
- trusted pids check: comparison of the trusted pid lists (in the
pidfield of the record). If at least 1 pid is equivalent, records match and the similarity relation is drawn. - instance type check: comparison of the instance types (indicating the subtype of the record, i.e. presentation, conference object, etc.). If the instance types are not compatible then the records does not match. Otherwise, the comparison proceeds to the next stage
- untrusted pids check: comparison of all the available pids (in the
pidand thealternateidfields of the record). In every case, no similarity relation is drawn in this stage. If at least one pid is equivalent, the next stage will be a soft check, otherwise the next stage is a strong check. - soft check: comparison of the record titles with the Levenshtein distance. If the distance measure is above 0.9 then the similarity relation is drawn.
- strong check: comparison composed by three substages involving the (i) comparison of the author list sizes and the version of the record to determine if they are coherent, (ii) comparison of the record titles with the Levenshtein distance to determine if it is higher than 0.99, (iii) "smart" comparison of the author lists to check if common authors are more than 60%.
Software
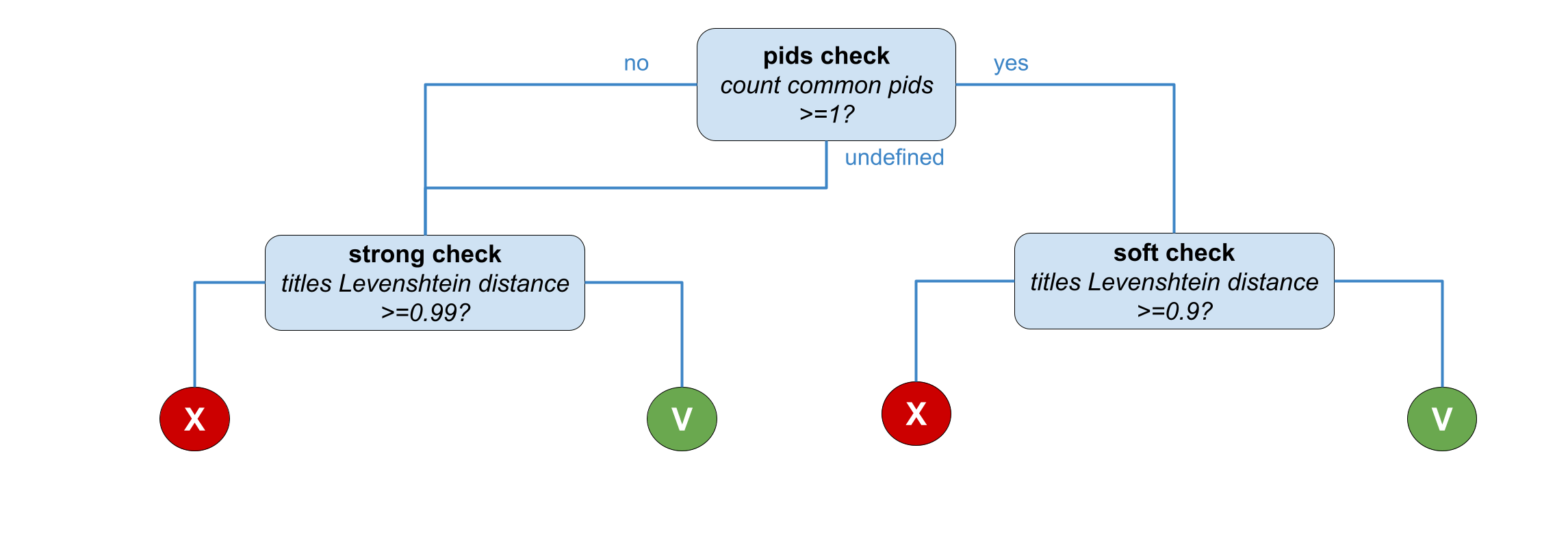
For each pair of software in a cluster the following strategy (depicted in the figure below) is applied. The comparison goes through different stages:
- pids check: comparison of the pids in the records. No similarity relation is drawn in this stage, it is only used to establish the final threshold to be used to compare record titles. If there is at least one common pid, then the next stage is a soft check. Otherwise, the next stage is a strong check
- soft check: comparison of the record titles with Levenshtein distance. If the measure is above 0.9, then the similarity relation is drawn
- strong check: comparison of the record titles with Levenshtein distance. If the measure is above 0.99, then the similarity relation is drawn
Datasets and Other types of research products
For each pair of datasets or other types of research products in a cluster the strategy depicted in the figure below is applied. The decision tree is almost identical to the publication decision tree, with the only exception of the instance type check stage. Since such type of record does not have a relatable instance type, the check is not performed and the decision tree node is skipped.
Duplicates grouping (transitive closure)
The general concept is that the field coming from the record with higher "trust" value is used as reference for the field of the representative record.
The IDs of the representative records are obtained by appending the prefix dedup_ to the MD5 of the first ID (given their lexicographical ordering). If the group of merged records contains a trusted ID (i.e. the DOI), also the doi keyword is added to the prefix.