Organizations
The organizations in OpenAIRE are aggregated from different registries (e.g. CORDA, OpenDOAR, Re3data, ROR). In some cases, a registry provides organizations as entities with their own persistent identifier. In other cases, those organizations are extracted from other main entities provided by the registry (e.g. datasources, projects, etc.).
The deduplication of organizations is enhanced by the OpenOrgs, a tool that combines an automated approach for identifying duplicated instances of the same organization record with a "humans in the loop" approach, in which the equivalences produced by a duplicate identification algorithm are suggested to data curators, in charge for validating them. The data curation activity is twofold, on one end pivots around the disambiguation task, on the other hand assumes to improve the metadata describing the organization records (e.g. including the translated name, or a different PID) as well as defining the hierarchical structure of existing large organizations (i.e. Universities comprising its departments or large research centers with all its sub-units or sub-institutes).
Duplicates among organizations are therefore managed through three different stages:
- Creation of Suggestions: executes an automatic workflow that performs the deduplication and prepare new suggestions for the curators to be processed;
- Curation: manual editing of the organization records performed by the data curators;
- Creation of Representative Organizations: executes an automatic workflow that creates curated organizations and exposes them on the OpenAIRE Graph by using the curators' feedback from the OpenOrgs underlying database.
The next sections describe the above mentioned stages.
Creation of Suggestions
This stage executes an automatic workflow that faces the candidate identification and the duplicates identification stages of the deduplication to provide suggestions for the curators in the OpenOrgs.
Candidate identification (clustering)
To match the requirements of limiting the number of comparisons, OpenAIRE clustering for organizations aims at grouping records that would more likely be comparable. It works with four functions:
- URL-based function: the function generates the URL domain when this is provided as part of the record properties from the organization's
websiteurlfield; - Title-based functions:
- generate strings dependent to the keywords in the
legalnamefield; - generate strings obtained as an alternation of the function prefix(3) and suffix(3) (and vice versa) on the first 3 words of the
legalnamefield; - generate strings obtained as a concatenation of ngrams of the
legalnamefield;
- generate strings dependent to the keywords in the
Duplicates identification (pair-wise comparisons)
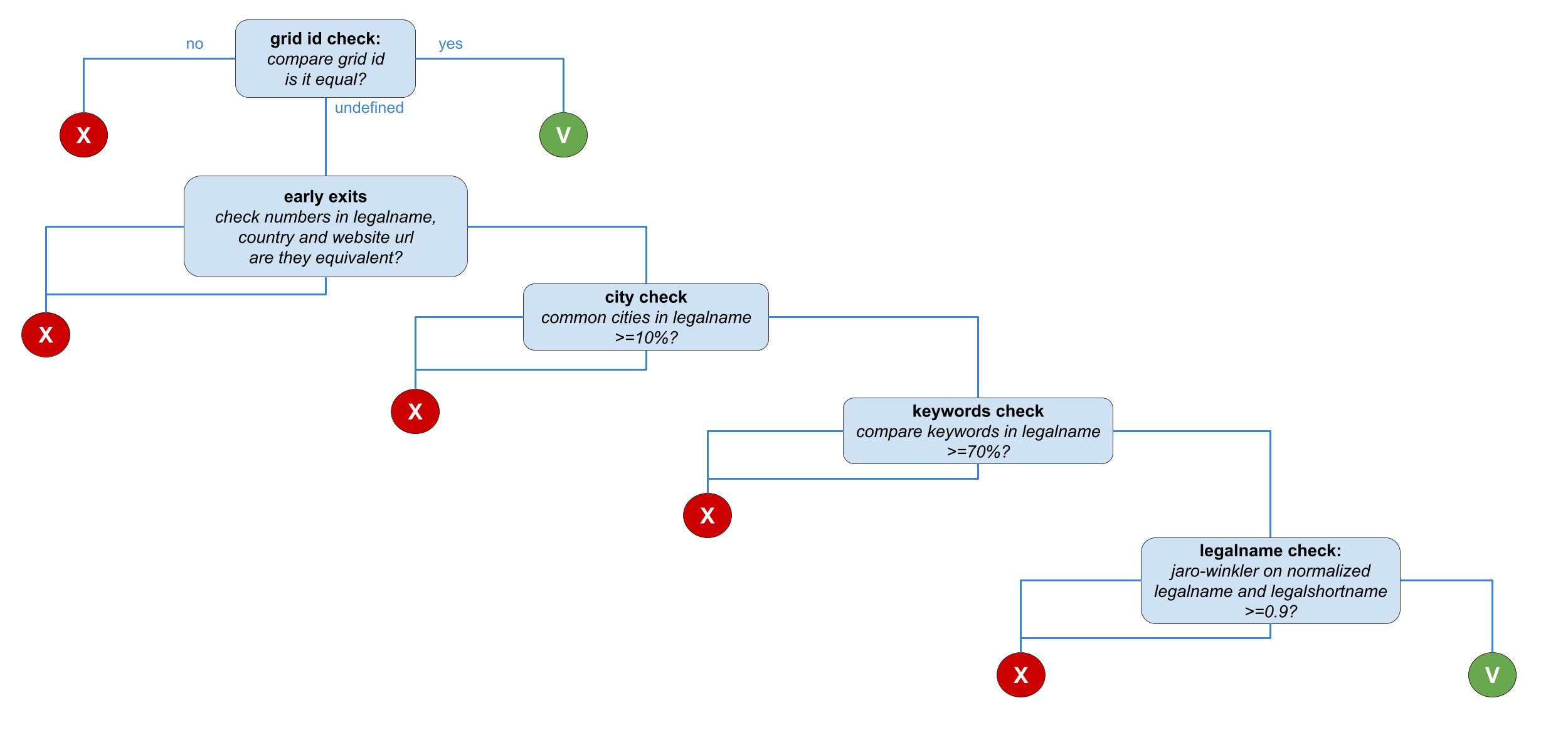
For each pair of organization in a cluster the following strategy (depicted in the figure below) is applied. The comparison goes through the following decision tree:
- grid id check: comparison of the grid ids. If the grid id is equivalent, then the similarity relation is drawn. If the grid id is not available, the comparison proceeds to the next stage;
- early exits: comparison of the numbers extracted from the
legalname, thecountryand thewebsiteurl. No similarity relation is drawn in this stage, the comparison proceeds only if the compared fields verified the conditions of equivalence; - city check: comparison of the city names in the
legalname. The comparison proceeds only if the legalnames shares at least 10% of cities; - keyword check: comparison of the keywords in the
legalname. The comparison proceeds only if the legalnames shares at least 70% of keywords; - legalname check: comparison of the normalized
legalnameswith theJaro-Winklerdistance to determine if it is higher than0.9. If so, a similarity relation is drawn. Otherwise, no similarity relation is drawn.
Data Curation
All the similarity relations drawn by the algorithm involving the decision tree are exposed in OpenOrgs, where are made available to the data curators to give feedbacks and to improve the organizations metadata. A data curator can:
- edit organization metadata: legalname, pid, country, url, parent relations, etc.;
- approve suggested duplicates: establish if an equivalence relation is valid;
- discard suggested duplicates: establish if an equivalence relation is wrong;
- create similarity relations: add a new equivalence relation not drawn by the algorithm.
Note that if a curator does not provide a feedback on a similarity relation suggested by the algorithm, then such relation is considered as valid.
Creation of Representative Organizations
This stage executes an automatic workflow that faces the duplicates grouping stage to create representative organizations and to update them on the OpenAIRE Graph. Such organizations are obtained via transitive closure and the relations used comes from the curators' feedback gathered on the OpenOrgs underlying Database.
Duplicates grouping (transitive closure)
Once the similarity relations between pairs of organizations have been gathered, the groups of equivalent organizations are obtained (transitive closure, i.e. “mesh”). From such sets a new representative organization is obtained, which inherits all properties from the merged records and keeps track of their provenance.
The IDs of the representative organizations are obtained by the OpenOrgs Database that creates a unique openorgs ID for each approved organization. In case an organization is not approved by the curators, the ID is obtained by appending the prefix pending_org to the MD5 of the first ID (given their lexicographical ordering).