Aggregation
OpenAIRE materializes an open, participatory research graph (the OpenAIRE Graph) where products of the research life-cycle (e.g. scientific literature, research data, project, software) are semantically linked to each other and carry information about their access rights (i.e. if they are Open Access, Restricted, Embargoed, or Closed) and the sources from which they have been collected and where they are hosted. The OpenAIRE Graph is materialised via a set of autonomic, orchestrated workflows operating in a regimen of continuous data aggregation and integration. [1]
What does OpenAIRE collect?
OpenAIRE aggregates metadata records describing objects of the research life-cycle from content providers compliant to the OpenAIRE guidelines and from entity registries (i.e. data sources offering authoritative lists of entities, like OpenDOAR, re3data, DOAJ, and various funder databases). After collection, metadata are transformed according to the OpenAIRE internal metadata model, which is used to generate the final OpenAIRE Graph, accessible from the OpenAIRE EXPLORE portal and the APIs.
The transformation process includes the application of cleaning functions whose goal is to ensure that values are harmonised according to a common format (e.g. dates as YYYY-MM-dd) and, whenever applicable, to a common controlled vocabulary. The controlled vocabularies used for cleansing are accessible at api.openaire.eu/vocabularies. Each vocabulary features a set of controlled terms, each with one code, one label, and a set of synonyms. If a synonym is found as field value, the value is updated with the corresponding term. In addition, the OpenAIRE Graph is extended with other relevant scholarly communication sources that need special handling, either because they do not strictly follow the OpenAIRE Guidelines or due to the vast amount of data of data they offer (e.g. DOIBoost, that merges Crossref, ORCID, Microsoft Academic Graph, and Unpaywall).
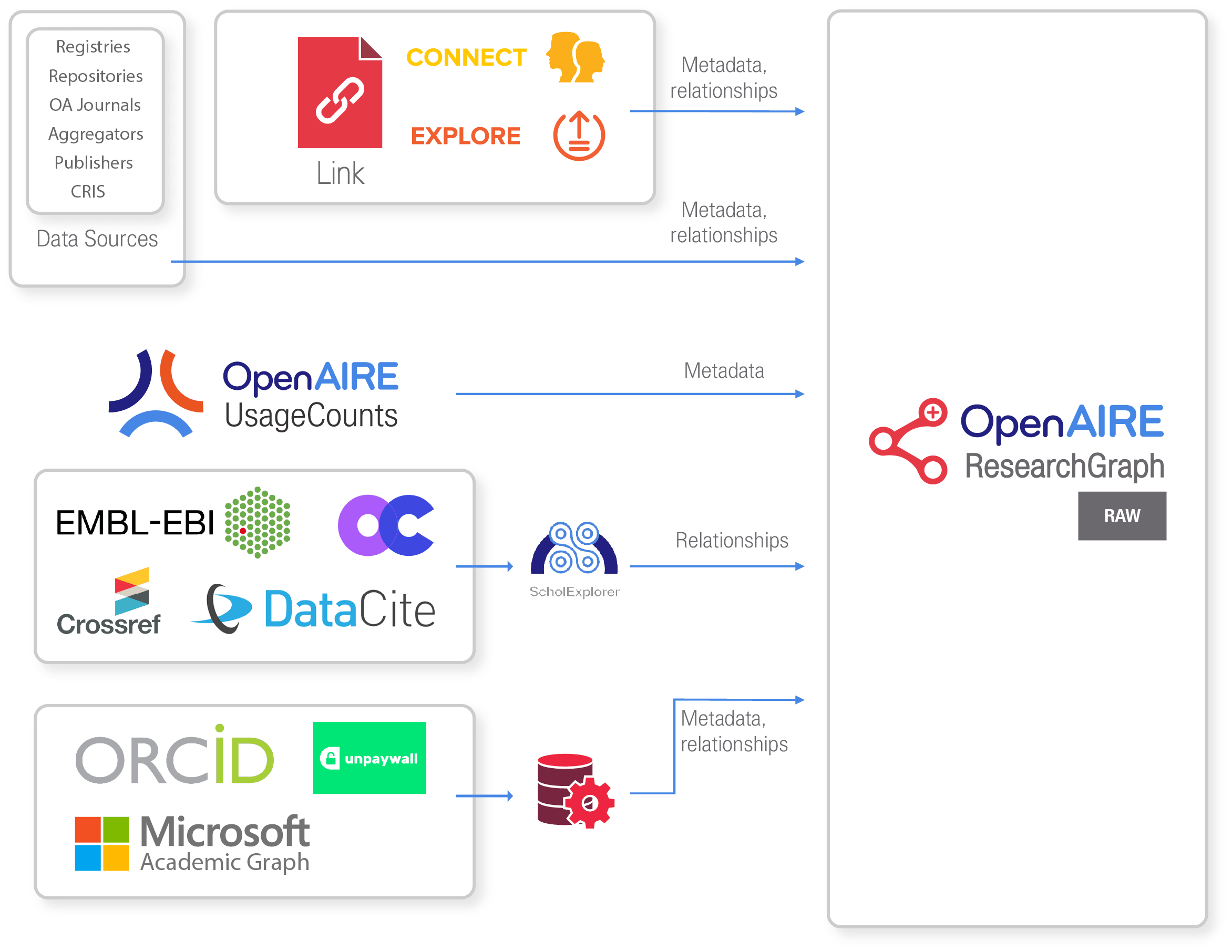
The OpenAIRE aggregation system collects information about objects of the research life-cycle compliant to the OpenAIRE acquisition policy from different types of data sources:
- Scientific literature metadata and full-texts from institutional and thematic repositories, CRIS (Common Research Information Systems), Open Access journals and publishers;
- Dataset metadata from data repositories and data journals;
- Scientific literature, data and software metadata from Zenodo;
- Metadata about data sources, organizations, projects, and funding programs from entity registries, i.e. authoritative sources such as CORDA and other funder databases for projects, OpenDOAR for publication repositories, re3data for data repositories, DOAJ for Open Access journals;
- Metadata of open source research software from software repositories and SoftwareHeritge
- Metadata about other types of research products, like workflow, protocols, methods, research packages
Relationships between objects are collected from the data sources, but also automatically detected by inference algorithms and added by authenticated users, who can insert links between literature, datasets, software and projects via the “Link” procedure available from the OpenAIRE explore portal. More information about the linking functionality can be found here.
What kind of data sources are in OpenAIRE?
Objects and relationships in the OpenAIRE Graph are extracted from information packages, i.e. metadata records, collected from data sources of the following kinds:
- Literature, Institutional and thematic repositories: Information systems where scientists upload the bibliographic metadata and full-texts of their articles, due to obligations from their organization or due to community practices (e.g. ArXiv, Europe PMC);
- Open Access Publishers and journals: Information system of open access publishers or relative journals, which offer bibliographic metadata and PDFs of their published articles;
- Data archives: Information systems where scientists deposit descriptive metadata and files about their research data (also known as scientific data, datasets, etc.).;
- Hybrid repositories/archives: information systems where scientists deposit metadata and file of any kind of scientific products, incuding scientific literature, research data and research software (e.g. Zenodo)
- Aggregator services: Information systems that collect descriptive metadata about publications or datasets from multiple sources in order to enable cross-data source discovery of given research products. Examples are DataCite, BASE, DOAJ;
- Entity Registries: Information systems created with the intent of maintaining authoritative registries of given entities in the scholarly communication, such as OpenDOAR for the institutional repositories, re3data for the data repositories, CORDA and other funder databases for projects and funding information;
- CRIS: Information systems adopted by research and academic organizations to keep track of their research administration records and relative results; examples of CRIS content are articles or datasets funded by projects, their principal investigators, facilities acquired thanks to funding, etc..
- Research Graphs: services that maintain an information space of (possibly interlinked) scholalrly communication objects. Examples are CrossRef, ScholeXplorer and OpenAIRE itself.
How does OpenAIRE collect metadata records?
OpenAIRE collects metadata records describing objects of the research life-cycle from content providers compliant to the OpenAIRE guidelines and from entity registries (i.e. data sources offering authoritative lists of entities, like OpenDOAR, re3data, DOAJ, and funder databases).
The OpenAIRE aggregator collects metadata records in the majority of cases via OAI-PMH, but also supports other standard exchange protocols like FTP(S), SFTP, and some RESTful API. The whole list of available and used collectors could be found in the RedMine Wiki - API Protocols
For additional details about the aggregation workflows, please refer to [2].
References
[1] Manghi, P., Artini, M., Atzori, C., Bardi, A., Mannocci, A., La Bruzzo, S., Candela, L., Castelli, D. and Pagano, P. (2014), “The D-NET software toolkit: A framework for the realization, maintenance, and operation of aggregative infrastructures”, Program: electronic library and information systems, Vol. 48 No. 4, pp. 322-354. doi:10.1108/prog-08-2013-0045
[2] Atzori, C., Bardi, A., Manghi, P., & Mannocci, A. (2017, January). "The OpenAIRE workflows for data management". In Italian Research Conference on Digital Libraries (pp. 95-107). Springer, Cham. doi:10.1007/978-3-319-68130-6_8