Deduplication
Metadata records about the same scholarly work can be collected from different providers. Each metadata record can possibly carry different information because, for example, some providers are not aware of links to projects, keywords or other details. Another common case is when OpenAIRE collects one metadata record from a repository about a pre-print and another record from a journal about the published article. For the provision of statistics, OpenAIRE must identify those cases and “merge” the two metadata records, so that the scholarly work is counted only once in the statistics OpenAIRE produces.
Methodology overview
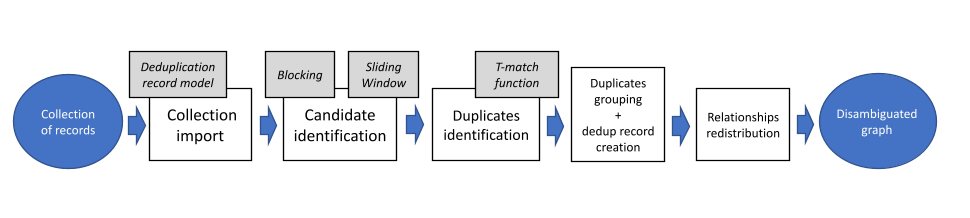
The deduplication process can be divided into five different phases:
- Collection import
- Candidate identification (clustering)
- Duplicates identification (pair-wise comparisons)
- Duplicates grouping (transitive closure)
- Relation redistribution
Collection import
The nodes in the graph represent entities of different types. This phase is responsible for identifying all the nodes with a given type and make them available to the subsequent phases representing them in the deduplication record model.
Candidate identification (clustering)
Clustering is a common heuristics used to overcome the N x N complexity required to match all pairs of objects to identify the equivalent ones. The challenge is to identify a clustering function that maximizes the chance of comparing only records that may lead to a match, while minimizing the number of records that will not be matched while being equivalent. Since the equivalence function is to some level tolerant to minimal errors (e.g. switching of characters in the title, or minimal difference in letters), we need this function to be not too precise (e.g. a hash of the title), but also not too flexible (e.g. random ngrams of the title). On the other hand, reality tells us that in some cases equality of two records can only be determined by their PIDs (e.g. DOI) as the metadata properties are very different across different versions and no clustering function will ever bring them into the same cluster.
Duplicates identification (pair-wise comparisons)
Pair-wise comparisons are conducted over records in the same cluster following the strategy defined in the decision tree. A different decision tree is adopted depending on the type of the entity being processed.
To further limit the number of comparisons, a sliding window mechanism is used: (i) records in the same cluster are lexicographically sorted by their title, (ii) a window of K records slides over the cluster, and (iii) records ending up in the same window are pair-wise compared. The result of each comparison produces a similarity relation when the pair of record matches. Such relations will be consequently used as input for the duplicates grouping stage.
Duplicates grouping (transitive closure)
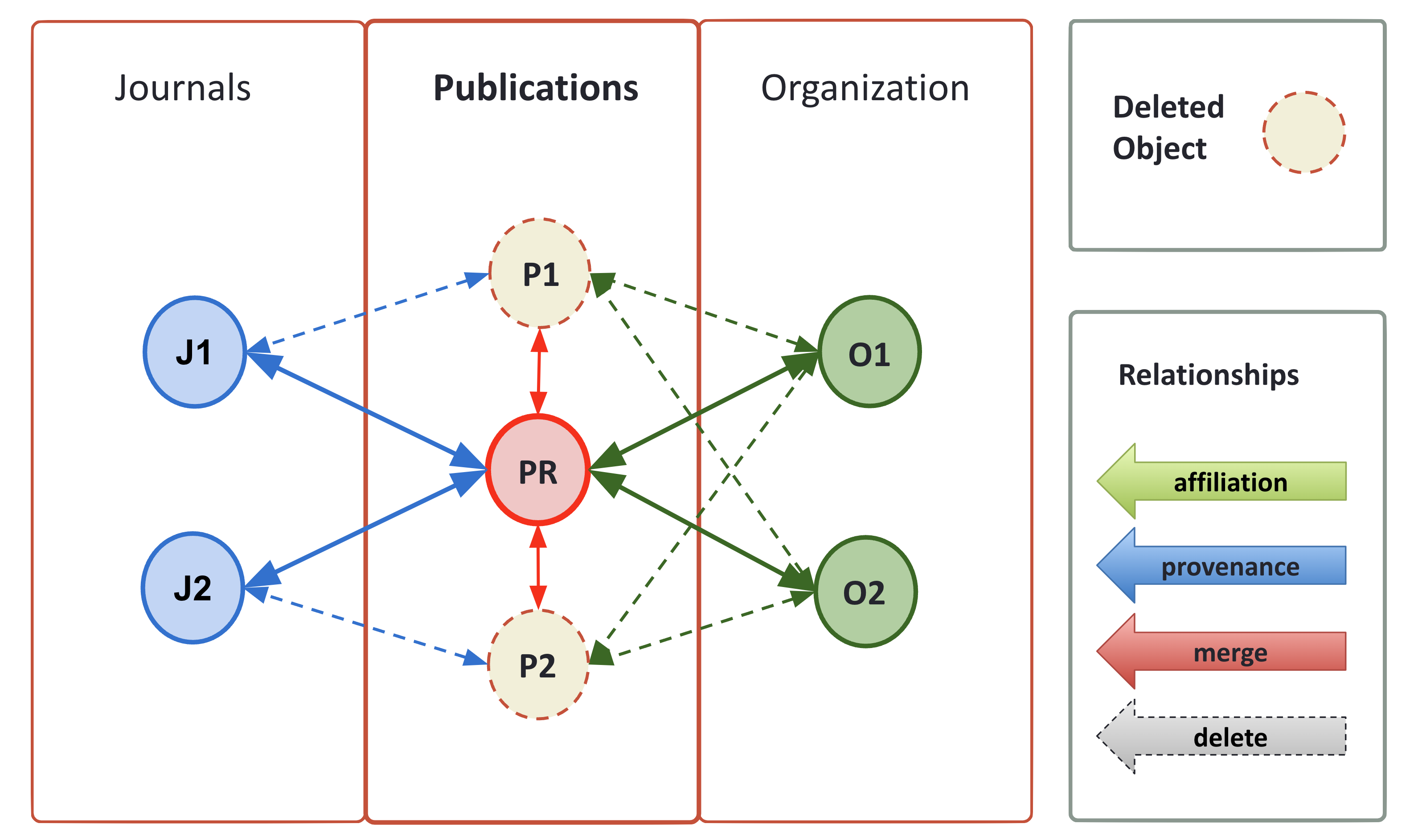
Once the similarity relations between pairs of records are drawn, the groups of equivalent records are obtained (transitive closure, i.e. “mesh”). From such sets a new representative object is obtained, which inherits all properties from the merged records and keeps track of their provenance.
Relation redistribution
Relations involved in nodes identified as duplicated are eventually marked as virtually deleted and used as template for creating a new relation pointing to the new representative record. Note that nodes and relationships marked as virtually deleted are not exported.